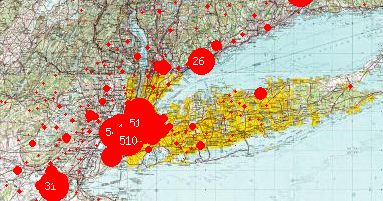
Liz on Many2Many posts a pointer to this geomapping of orkutsters. I spoke to my class Monday night about the ethical dimensions of getting at that data.
The minute I first signed on to Orkut, I realized that it would be a great source of info to mine for looking at several social sciency questions, so I did what every responsible researcher would do: I emailed Orkut asking for the data. It’s not an issue of invading the privacy of the users–they have clearly published their information to the public. However, Orkut’s TOS forbid scraping. I somehow doubt this map was created by typing the data by hand :). And now, a couple (?) weeks later, he (they) haven’t even bothered responding.
That isn’t really a surprise. I ran into the same thing with Slashdot, and colleagues have faced the same difficulty with Ebay. The only exception I’ve seen was wikipedia, who were very helpful. More irksome is that this data is often released to some researchers, but not others. I understand that, to a certain extent, but it is so against the kind of ethic of sharing in the academic world that it comes as a surprise when the same isn’t true among those running websites–especially those serving the open source community, as in the case of Slashdot.
So, what do I do now. I personally have little ethical difficulty with scraping Orkut. Frankly, it is the same as hiring a student to sit there and transcribe it. I now hear that similar projects that did scrape sites faced no serious impediment from their human subjects panels. So now I feel like I have shot myself in the foot by not collecting that data and mapping it: something I had hoped to do early on.
I’m curious what others think of this. Is there an ethical issue in violating the ToS? Does this make me a bad researcher? What is the legal position? How long will it take after asking this publicly before I am exiled from Orkut? Or better yet, since private emails go unanswered, mightn’t someone from Orkut respond publicly to the issue? (Fat chance?) If I did scrape the data, should it then be made available as a database? Only to other researchers? (The site hosting this data makes me wonder if such questions are moot. I somehow doubt that “datapimp” is very fussy about his customers…)
6 Comments
Your post reminded me of a 1999 article in cybersociology (a zine that appears to be quite inactive now): “Behavior in Public? Ethics in Online Ethnography”. Although the author doesn’t address TOS issues, I think the article would suggest that, at least from an ethical research standpoint, privacy really is a concern in this case.
Orkut technically is a private community, albeit one that everybody knows about. As the author of the piece writes, while public places have long been acceptible sites for research
I think it’s a real dilemma; something like Orkut is a mine full of data, but I don’t think the privacy concern is easily dismissed. The datawhorehouse map, for instance, clearly violates the kind of privacy requirements that bind researchers like you and me — it lets me identify, by name, of all Orkut members who live in my area code. That’s the kind of disclosure that would never make it past IRB, I imagine — Certainly, a project could be conducted so that the resulting data did not disclose individually-identifying information, which makes this a dilemma in particular for social scientists like us who are bound by institutional and ethical requirements. I’d be interested in hearing more about similar projects and how they were presented to human subjects.
That aside, I’m not sure what to make of the TOS issue. I have to admit that it seems sort of clear cut. They own the information, and they forbid scraping it, and would probably make an economic argument about how it’s very valuable information to them. I know there’s debate about the enforceability of click-through terms of service; if you have to agree to the TOS to join, I expect they’d at least float a legal issue. On the other hand, as a member of the community you’re allowed to access that information, presumably for any reason you please. If you don’t “scrape” it, can you just “transcribe” it? (Similarly, Sociological Abstracts and other databases have started to prohibit “systematic and programmatic” use of their services; does that mean systematic sampling and studying of subjects and cross-citation by people who do bibliometrics is disallowed?)
I keep thinking back to the idea that this whole dilemma really only exists because you have to pay attention to institutional rules, so it’s especially frustrating that datawhorehouse can come along all willy-nilly and bypass all those rules.
This is a really interesting set of issues — thanks.
Thank you for your thought-provoking comment.
It is really a question of second-guessing the expectations of the users. I see how it could be considered a less-than-entirely public space, though I stand by my assertion that this is a public enough disclosure that it should be fair game. (Though, when I originally wrote this, I had softened that statement much more, expressing uncertainty over the privicy question.)
I would never even think of reporting names, or individualized data of any sort. I guess I just took that as a given. That said: If I want to know who among the 35K people live in Buffalo, it is the default search on Orkut.
The students in my class all had interesting comments: most of which had to do with ways of getting around IRB rather than respecting the privacy rights of our subjects, I’m sorry to say. None of these were particularly compelling.
If I were using the data properly, I don’t think it would have much of an effect on their business, really. I know that Ebay has gone after someone for scraping, but I think that they were either using the data to drive traffic to their site or using it to game Ebay. I probably did click through an agreement to the ToS, without really thinking about it though.
I think you’re right to say that the data probably wouldn’t have much of an effect on Orkut’s business — but whether they’d actually cop to that is another question! (especially given how social networks have become all “big business” all of a sudden)
The GeOrkut script was basically an experiment which was shared with members of the orkut community. The URL was disseminated to a few select people via orkut email, and also posted to an Orkut community board. All references to the link were contained within the Orkut website, and we could make the assumption that those viewing the Datawhorehouse GeOrkut page were all members of Orkut. Therefore, we could make a claim that the information was still kept within the private Orkut community. At some point people began to post the link on their public blogs (outside of the orkut community). Also, people emailed the link to their friends. This is when the traffic to my website exploded. Having access to the web server referrer logs, I can prove that over 90% of the traffic coming to the page originated from links in public blogs.
The argument in the above thread is quite an interesting one. It all seems to boil down to the question of whether or not Orkut and the information contained within is considered private or public. And if it is considered private, is the migration of this data out of the space considered an ethical violation? Also, to determine that,
one needs to define where lies the borders of this virtual space.
Is user information public or private?
I see the Orkut user information as being analogous to a name tag worn by an attendee at a business convention. To make this situation a little more controversial, let us further specify that this is a sex convention taking place at the Javitts center. Display of attendees? personal information is completely voluntary. It can be observed and readily collected by third parties without any hindrance. Members within the convention do not feel any privacy violation
when communicating or sharing information within confines of the meeting space. Within the community, the information is considered public.
Where defines the boundaries of the community?
Can a border be defined by the level of difficulty in which it is to obtain the information?
Orkut provides a search feature which allows users to browse all members within the radius of specified zip code. This is essentially the same function provided by the GeOrkut application (though much less efficiently). The user information is made available to anyone who is currently an Orkut member.
Is the border a physical or virtual one?
Let us say that after the convention, there is an after-expo party at a different venue.. Webster Hall perhaps. The attendees do not feel violated as they continue to share information outside of the Javitts center.. because they are still within the confines of their private group or space. A virtual space. However if their names were published in the New York Times the following morning, there might be some objection. In this example, community borders are virtual and not physical.
The issue does become more complex within cyberspace. If we started a discussion within an Orkut community group, and then continued the conversation on this blog website, would that be considered an illegal export of the thread? At what point is the export considered illegal? When the packets leave the server, the router, or the local network? The boundaries of cyberspace have yet to be defined.
At one point does a secret cease to become a secret? Judging from my web server logs, and in reference to my first paragraph above, it appears that the Orkut user information (if it can be considered private) was not introduced outside of the private Orkut community until after the GeOrkut link was posted to multiple public blogs around the net. If there is to be considered a point at which private information was divulged, I think this is where it occurred.
I need to list the trackbacks on the comments pages. Anyway, I’ve bumped this discussion up to a response on the main page here.
I believe you nailed it when you wrote that pulling data was no different than having a student find and transcribe.
There is NO difference.
The privacy issue is the only valid point to consider, and I would tend to agree with you that the data is public NOT private.
One Trackback
Is it OK to publish Orkut-collected datasets?
Alex Halavais’ blog is home to an interesting discussion of the privacy / information property issues around the Orkut geomap we wrote about two weeks ago : part one, part two. It’s worth noting that Rolan (the datapimp / Orkut…